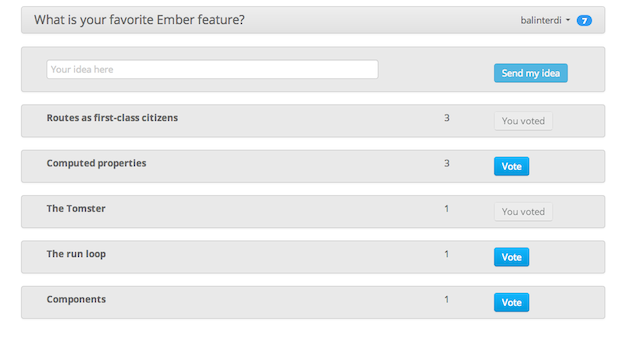
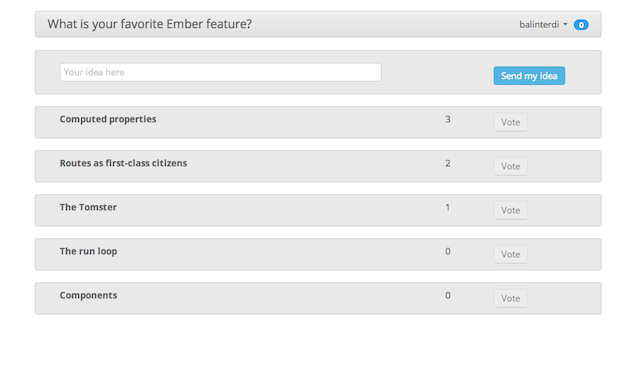
Given that I started engaging with web sites in the early 2000s there are still some things today that I constantly marvel at. One of these things is real-live update, the absolutely wonderful experience that I’m looking at a page and it displays a change due to an action of another user right in front of my eyes, without me hitting refresh.
Discourse, being a state-of-the-art forum software does this, too, and, provided my enthusiasm with all things that bring the web alive, I wanted to understand how that works. More specifically I wanted to understand how displaying new posts for the topic I am looking at can work its magic.
In the following post, I want to lead you through the whole process so that you see exactly how the pieces fit together. In fact, that may be the thing I enjoy most as a developer. Being able to take apart a complex application and gain the comprehension of how the individual pieces function and how they are orchestrated to make a complex system work.
Tools
Discourse is built on Ruby on Rails and Ember.js, two fantasic frameworks. Given my recent fascination with front-end development, and Ember.js in particular, I’ll focus on the front-end part here and only talk about the back-end mechanism as much as it is needed to see the whole picture.
Consequently, some knowledge about Ember.js is assumed. You can go through the Getting Started guide on the official Ember.js site or -if you prefer showing to telling- sign up to my mailing list to watch a series of screencasts to get a basic grip on Ember.js architecture as we go through the building of an application.
Message bus
Discourse uses a ruby gem (library) called message_bus that enables listeners to subscribe to any channel of their liking and get notified about events happening on that channel.
It also includes a javascript lib to allow connecting to the message bus from the client-side application. That’s what Discourse uses from the Ember.js app. Let’s see how.
Subscribing to new posts on a topic
When the user navigates to a topic page, the topic route gets activated and its
hooks run. After resolving the model, the setupController which, as its name
indicates, sets up the controller belonging to the model. It, among other
things, calls the subscribe method on the controller, see below:
1 2 3 4 5 6 | |
The controller for the model is Discourse.TopicController, so next we will look into that:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
The controller subscribes to the channel /topic/<topic_id>. The client polls
the message bus for potential new messages every 15 seconds. You can see the XHR
calls in the console of your browser:

When something is published to that channel, the callback function gets called back with the data related to that event. The data, in that case, is going to be the new post record. When the callback is fired, we call the triggerNewPostInStream method on the postStream with the id of the post. What does triggerNewPostInStream do, then? We can check that in the PostStream model.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
The docstring is quite revealing. If the post id is already in the stream, we don’t do anything. If it is not, we add it to the stream (an Ember array). If the loading of posts has finished, we are ready to append the new posts to the stream.
Notice we are adding post ids, not actual post records so the next investigation step is to explore how ids get turned into records.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | |
The above appendMore method is responsible for retrieving the post ids that
have to be added below the currently visible posts and turning these ids into
actual post records.
We are getting close now, but let me speed things up a bit by only explaining the
process but not showing all the code which makes it so that the new post objects
are finally pushed to the posts array from where they will be finally
displayed. (If you are such a code untangler as I am, and would like to see the
code, it is right here)
What happens is that the new posts get displayed in windows, not one by one.
This window is kept updated in the nextWindow property, from the stream we
pushed post ids into. It is the slice in this stream that starts at the last
loaded post id and has a maximum length of posts_per_page, a configuration
setting. This construct also makes it possible, quite ingeniously, for this
same code to load the next batch of posts to the page as the user scrolls down.
The window still contains ids and to fetch the related post records an identity
map (yes, Discourse has its identity map implementation,
too!) is used via the findPostsByIds method. Once the records are retrieved ,
they are each passed to the appendPost method that just pushes them to the
posts array.
Displaying the new post in the topic stream
The only thing remains to be seen for the whole picture to be clear is how the stream of posts is displayed in the browser. The template that renders the topic, along with its posts, is the topic template.
The relevant part of the template is below:
{{#unless postStream.loadingFilter}}
{{cloaked-collection cloakView="post" idProperty="post_number" defaultHeight="200" content=postStream.posts slackRatio=slackRatio}}
{{/unless}}If the post stream is not loading, we render the posts through the cloaked
collection. I will not go into details about what
cloaked-collection does, (but I highly recommend a blog
post on it by its author, @eviltrout), the important thing in the
current discussion is that it renders the post template (cloakView=”post”) for
each post from postStream.posts (content=postStream.posts).
That is where the two parts come together. Since a binding is established with the above handlebars line to the posts property of the postStream, every time new posts are added (see how in the first part of the walkthrough), the collection is going to be rerendered and consequently the posts appear in “real-time”. The magic of Ember.js bindings.
In parting
I skipped over a couple of things so that this post does not turn into a chapter of a novel, but I hope that my walkthrough could let you peek behind the curtains and see how such a miraculous feature is made possible.
The key takeaway is that building with the right tools (namely the message bus and the solid foundations of Ember.js), which a lot of people have put an enormous amount of time into, makes such a killer feature within your reach. Not easy, but definitely doable.